AI Factories: An Integrated Infrastructure Solution by Hydra Host and USD.AI
With contribution of



AI Factories: An Integrated Infrastructure Solution by Hydra Host and USD.AI
The data center industry is undergoing its most significant transformation since the cloud era began. Facilities that once existed to store information are becoming factories that manufacture intelligence—and the economics of building them look nothing like traditional infrastructure finance.
This shift has created a gap between the capital required to deploy AI compute and the financing structures available to fund it. Hydra Host and USD.AI solve this by integrating the two most critical components of the stack, guaranteed chips and flexible capital, enabling operators to bypass the "Year of Delays" and build at the speed of software.
The shift from cost center to revenue generator
For decades, data centers existed primarily to store and retrieve information. They were expenses on a balance sheet, necessary infrastructure that supported other business activities but didn't generate revenue on their own. The rise of AI compute has changed this equation entirely.
An AI Factory is a data center designed specifically to produce intelligence. Rather than passively holding data, these facilities actively manufacture something valuable: trained models, inference results, and AI tokens. Every GPU hour sold to a customer represents a product leaving the factory floor, which means the facility itself becomes a direct source of income.
This shift matters because it transforms how operators think about their buildings and equipment. A traditional data center might measure success by uptime and cost efficiency. An AI Factory measures success by throughput and revenue per rack.
The physical differences are equally significant. Traditional servers might draw 5–10 kilowatts per rack, while AI workloads often require 50 kilowatts or more. Cooling systems that worked fine for conventional computing can't handle the heat density of modern GPU clusters. And because AI training involves constant communication between thousands of processors, the networking requirements are far more demanding.
Here's what distinguishes an AI Factory from a conventional data center:
- Power density: AI clusters consume electricity at rates that would overwhelm standard facilities
- Liquid cooling: Air cooling alone can't dissipate the heat from high-performance GPUs, driving 22% of data centers to adopt liquid cooling solutions as of 2025.
- InfiniBand networking: Distributed training workloads require low-latency, high-bandwidth connections between GPUs
- Specialized floor plans: Rack layouts and power distribution are designed around GPU clusters rather than general-purpose servers
These requirements create a distinct asset class. You can't simply retrofit an old data center and call it an AI Factory. The facilities look different, operate differently, and generate returns through entirely different mechanisms. This distinction has major implications for how AI Factories get financed, a topic we'll return to shortly.
Why 2026 is shaping up to be the year of delays
Demand for AI compute continues to grow faster than the industry can build capacity. However, the bottleneck isn't a lack of money or ambition. It's a physical constraint in the manufacturing process itself.
Two components are particularly scarce. The first is CoWoS packaging, which stands for Chip-on-Wafer-on-Substrate. This advanced manufacturing process connects GPU dies to high-bandwidth memory, and it's essential for producing the most powerful AI chips. TSMC, the primary manufacturer, has expanded capacity repeatedly, but demand still outpaces supply. The second constraint is HBM3E memory, the specialized high-bandwidth memory that modern GPUs require. Allocation for this memory is essentially spoken for by hyperscalers through 2026.
What does this mean for someone trying to build an AI Factory? Even with capital in hand, securing the actual hardware can take 12–18 months or longer. During that waiting period, the money sits idle while competitors who secured earlier allocation capture market share.
The financial impact is substantial. Facilities without guaranteed hardware allocation are currently trading at significant discounts to their theoretical value. Investors have learned that a data center without GPUs is just an expensive building. Access to hardware has become a primary driver of valuation, sometimes more important than the real estate itself.
This supply constraint creates a two-sided problem. On one hand, operators can't deploy capital without chips. On the other hand, chip suppliers want proof of funds before committing allocation. Breaking this cycle requires solving both sides simultaneously.
Why traditional finance struggles with AI Factories
Banks have been financing data centers for decades, but AI Factories present unfamiliar challenges. Traditional lenders evaluate facilities based on real estate fundamentals: location, construction quality, lease terms with tenants, and the creditworthiness of the operator. GPUs don't fit neatly into this framework.
A GPU is a depreciating asset with a useful life of roughly three to six years. It generates revenue through compute services, but that revenue depends on utilization rates, electricity costs, and market pricing for AI workloads. Most banks don't have underwriting models for this kind of asset. As a result, they decline to lend against the assets themselves, instead requiring personal recourse from borrowers or proof of historical income that is not available.
The impact falls hardest on emerging operators. Hyperscalers like Microsoft, Google, and Amazon can fund AI infrastructure from their balance sheets or through investment-grade corporate debt at favorable rates. Smaller "Neocloud" operators, independent GPU cloud providers building the next generation of AI infrastructure, face a different reality. Financing for these companies are often entirely unavailable, or come in the form of predatory lease structures with high breakage and take-out costs that push cost of capital in excess of 20%.
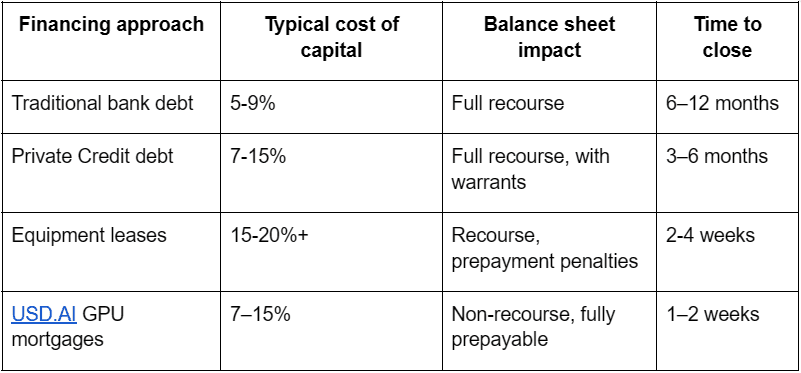
USD.AI approaches this problem differently. Rather than lending against the operator's corporate balance sheet, USD.AI treats GPUs as a standalone asset class that generates predictable cash flows. The financing structure uses a Special Purpose Vehicle (SPV)—a legal entity created specifically to hold the GPUs and the associated debt. Lease revenues from the GPUs pay down the loan, which means the operator's other assets aren't at risk if something goes wrong.
This structure reduces cost of capital and risk significantly for emerging neoclouds, enabling the growth of their business without requiring highly dilutive equity capital, personal guarantees for debt financing, or the use of predatory equipment leases. The result is that smaller operators can compete with hyperscalers on unit economics, even without the same balance sheet strength.
How Hydra Host and USD.AI work together
The AI Factory market faces a frustrating paradox. Financing requires proof of hardware allocation, but hardware allocation requires proof of financing. Many operators get stuck in this loop, unable to move forward on either front.
Hydra Host and USD.AI tackle both sides of the equation. Hydra Host handles hardware sourcing through direct relationships with NVIDIA and access to secondary markets where GPUs trade between operators. USD.AI provides the financing structure, with debt secured by the GPUs themselves rather than the operator's balance sheet.
Together, the two companies offer what amounts to a turnkey solution for AI Factory deployment. The combined approach handles:
- Hardware procurement: Direct allocation from manufacturers plus secondary market access
- Financing structure: Non-recourse debt secured by the GPUs and their lease revenues
- Legal framework: Standardized SPV structures and custody arrangements that work across jurisdictions
- Operational integration: Coordination between hardware delivery, facility readiness, and capital deployment
This integration matters because timing is critical. A financing commitment that arrives three months after hardware delivery doesn't help. Similarly, hardware that shows up before the facility is ready creates storage and insurance complications. Coordinating these elements requires close collaboration between the sourcing and financing partners.
The model is designed to be flexible across different scales and geographies. Whether the project involves a 50-megawatt cluster in Texas or a sovereign cloud deployment in Europe, the same basic structure applies. Operators can focus on utilization and customer acquisition rather than navigating supply chain logistics or banking relationships.
Case Study: Lyceum Sovereign AI Deployment
In 2025, Hydra Host and USD.AI partnered to deliver the Lyceum project, an 8-node NVIDIA HGX B200 SXM liquid-cooled cluster with InfiniBand. The newest European Sovereign AI Cloud initiative building AI infrastructure under European control rather than depending on US hyperscalers. This deployment demonstrates how the integrated sourcing and financing model works in practice, delivering speed and capital efficiency that traditional approaches cannot match.
The project launched in Q4 2025 with a $3 million proof-of-concept deployment that Hydra Host sourced its allocation channels, while USD.AI structured the financing through a GPU-backed mortgage. The entire process, from initial commitment to operational deployment, took four months.
That timeline stands in contrast to the 18–24 months that a hyperscaler-dependent approach might require. The speed came from having both sourcing and financing aligned from the start, rather than sequencing them one after the other.
For governments and enterprises concerned about data sovereignty, this model offers an alternative to relying on US cloud providers. The infrastructure remains under local control, the data stays within European jurisdiction, and the financing structure doesn't require dependence on foreign capital markets.
Exploring GPU-backed financing for your next deployment? Learn more about structuring your AI Factory
The path forward for AI infrastructure
The traditional model of bank-financed data centers is giving way to something more specialized. AI Factories require different physical infrastructure, different operational expertise, and different financing structures than conventional facilities.
As supply constraints intensify through 2026, the operators who succeed will likely be those who solve both the sourcing problem and the financing problem together. Waiting for one to resolve before addressing the other means falling behind competitors who moved faster.
Hydra Host and USD.AI provide the blueprint for this new era. By interlocking guaranteed sourcing with specialized GPU debt , this alliance allows operators to deploy capital and compute on compressed timelines. For an industry where timing determines market position, this integrated speed is the difference between capturing the opportunity and being left in the queue.
